
최근에 AWS에서 발표한 CloudTrail Lake 공지를 보고 느낀 점은 기존에 리전, 계정별로 관리하는 테이블에 대한 부담 없이 손쉽게 Athena 같은 환경을 구축할 수 있어서 편리하겠다 였습니다. 그래서 곧바로 설정하고 CloudTrail Lake를 사용해봤는데, 느낀 점은 편리하면서 비싸다 입니다. 왜 그렇게 생각했는지 하나하나 살펴보도록 하겠습니다.
CloudTrail Lake 설정 및 사용
CloudTrail Lake의 설정은 매우 간단합니다. 조직 관리자 혹은 보안 계정에서 조직 전체에 대한 이벤트 데이터 저장소를 구성하기만 하면 됩니다. 이름과 보존 기간, 리전, 조직 계정 활성화 여부 및 이벤트 유형만 결정하면 곧바로 생성됩니다. 구체적인 설정 가이드는 공식 블로그의 글을 참고하시기 바랍니다. [바로가기]

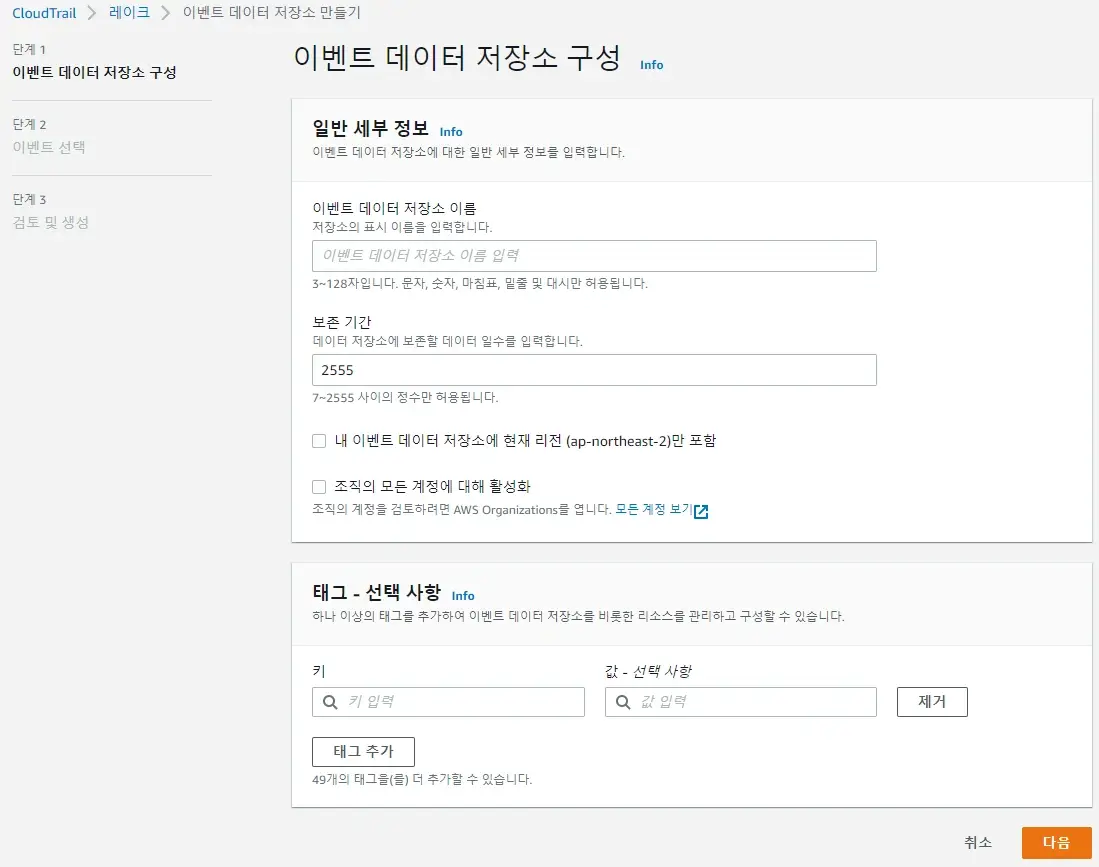
이벤트 데이터 저장소는 아마도 S3일 것이지만, AWS에서 자체적으로 관리하기 때문에 저장소 자체에 직접 접근하는 것은 불가능합니다. 즉, 데이터 변조는 아예 불가능하며 CloudTrail Lake의 권한이 없으면 데이터 조회를 할 수가 없습니다. 이런 면에서 보안은 기존의 CloudTrail보다 더 낫다고 볼 수 있습니다.

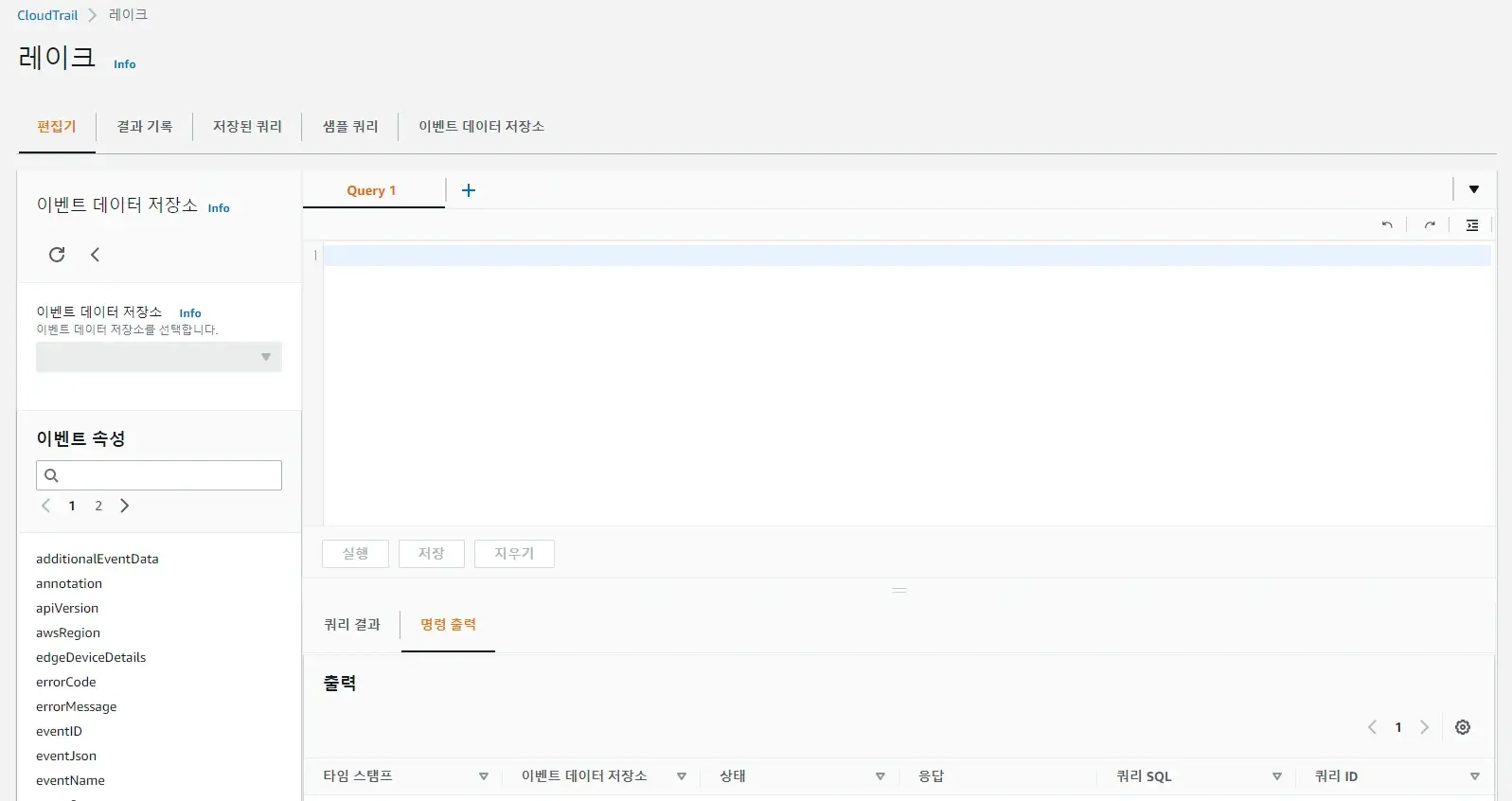
약간의 시간이 지나서 데이터 저장소가 생성되고 이벤트가 저장되기 시작하면 저장된 데이터에 대한 표준 SQL 기반의 쿼리를 할 수 있습니다. 쿼리 에디터는 기존의 Athena와 굉장히 유사한 UI를 가지고 있습니다. 테이블 이름 대신에 이벤트 데이터 저장소의 고유 아이디를 입력하고 사용하면 됩니다. 참 쉽죠?
설정이 이렇게나 간편하고 조직의 모든 계정과 모든 리전에 대한 CloudTrail 이벤트 로그가 쿼리를 통해서 검색 가능해지는데 조심해야 할 점이 하나 있습니다. 바로, 사용하기에 따라서 비용이 과도하게 늘어날 수 있다는 것입니다.
CloudTrail Lake 비용
CloudTrail Lake의 비용은 아직 한국어로 업데이트가 되지 않아서 영어로 확인해야 합니다. [바로가기]

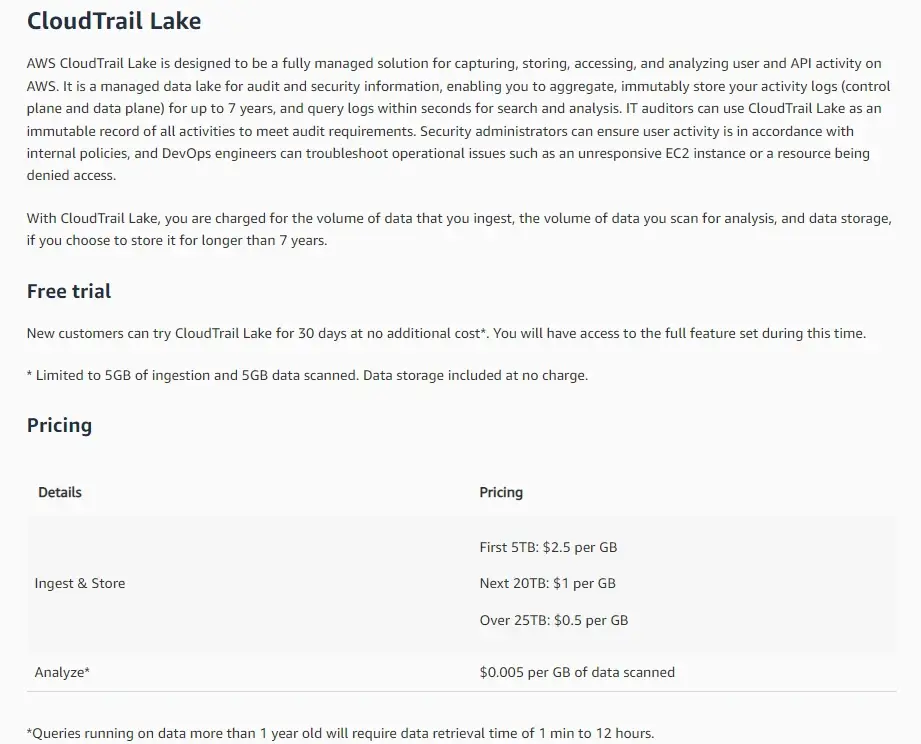
무료 기간이 있기는 하지만, 이후에는 매 월 1GB당 $2.5의 비용을 지불해야 합니다. 쿼리 비용은 Athena와 동일하며 별도로 지불해야 합니다. 기존의 CloudTrail 비용은 이벤트 데이터 건별로 발생하기 때문에 비교하기가 약간 어렵습니다. 그래서 제가 관리하는 계정의 2021년 12월 ap-northeast-2 리전 데이터를 기준으로 가상 비교를 해봤습니다. 기준 데이터의 크기는 5.2GB, 데이터의 건수는 3350만 건입니다.
- CloudTrail with S3
- Free for Ingest (First copy of management events only)
- $0.025/GB * 5.2GB = $0.13
- CloudTrail Lake
- $2.5/GB * 5.2GB = $13
위 계산은 오직 Management events에 한정됩니다. 만약 이와 동일한 양의 Data events가 있다고 가정하면 다음과 같은 비용이 발생할 것입니다.
- CloudTrail with S3
- $0.1/100k * 33500k = $33.5
- $0.025/GB * 5.2GB = $0.13
- CloudTrail Lake
- $2.5/GB * 5.2GB = $13
결과가 묘하게 나왔습니다. Management events만 사용하는 경우라면, 전자가 압도적으로 유리한 반면에, Data events까지 수집하면서 그 데이터의 양이 많으면 후자가 유리할 것으로 기대됩니다. 물론, Data event 한 건당 데이터의 크기가 다를 수 있기 때문에 이에 대한 분석은 직접 진행해보셔야 하겠습니다.
이 외에도 외부 프로그램을 연동하여 CloudTrail을 분석하거나 가공하고자 한다면 기존에는 S3에 직접 파일 형태로 접근이 가능했으나 CloudTrail Lake는 반드시 쿼리를 수행해아만 데이터를 얻을 수 있습니다. 그렇다는 것은 결국 외부 Integration을 위해서 추가적인 비용 소모가 불가피하다는 뜻입니다.
CloudTrail과 Athena Partition
비용과 편리함 중에 어떤 것을 고를 수 있을까요? Trade off라고 생각할 수 있지만, 기존 CloudTrail에서도 Athena를 통해서 충분히 훌륭한 쿼리 환경을 구축할 수 있습니다. Athena Partition을 이용하여 모든 데이터를 하나의 테이블로 묶으면 CloudTrail Lake와 유사한 환경이 구축되기 때문에 Management events만 수집하는 경우에는 양쪽의 모든 장점을 취할 수 있습니다.
먼저, AWS 조직 계정에 대한 CloudTrail을 설정합니다. 버킷 경로를 s3://cloudtrail-bucket/AWSLogs/o-rgid/ 라고 하겠습니다. 그러면 버킷의 o-rgid/ 하위 경로에 다음과 같은 prefix를 가지고 events가 저장됩니다.
s3://cloudtrail-bucket/AWSLogs/o-rgid/<account>/CloudTrail/<region>/<year>/<month>/<day>/
Code language: HTML, XML (xml)Athena에서는 여러 형태의 데이터 파티션을 제공하는데, 여기서는 enum과 timestamp 타입의 파티션을 정의하고 사용할 수 있습니다. 먼저 enum으로 정의할 파티션은 account와 region입니다. account는 조직의 하위 계정들을 전부 혹은 필요한 계정만 나열하고, region도 필요에 따라 목록을 제공하면 됩니다.
'projection.account.type'='enum',
'projection.account.values'='account1,account2,account3',
'projection.region.type'='enum',
'projection.region.values'='ap-northeast-1,ap-northeast-2,ap-northeast-3,ap-south-1,ap-southeast-1,ap-southeast-2,ca-central-1,eu-central-1,eu-north-1,eu-west-1,eu-west-2,eu-west-3,me-south-1,sa-east-1,us-east-1,us-east-2,us-west-1,us-west-2',
Code language: JavaScript (javascript)timestamp 파티션은 연, 월, 일 형태로 정의할 것이므로 형태와 간격, 시작일과 종료일을 정해주면 됩니다. 종료일의 경우에는 NOW를 통해서 당일까지 지정이 가능합니다.
'projection.timestamp.type'='date',
'projection.timestamp.interval.unit'='DAYS',
'projection.timestamp.interval'='1',
'projection.timestamp.format'='yyyy/MM/dd',
'projection.timestamp.range'='2020/01/01,NOW',
Code language: JavaScript (javascript)연, 월, 일을 별도의 파티션 컬럼으로 지정할 수 있지만, 그렇게 하면 복잡도가 증가하고 대소 비교가 어려워지는 문제가 있습니다. 위와 같이 timestamp를 파티션으로 정의하면서 partition projection 옵션을 제공하면 대소비교와 like 모두 필요한 파티션만 읽을 수 있습니다. 이제 이런 테이블 설정을 모아서 다음과 같이 하나의 테이블을 생성할 수 있습니다.
CREATE EXTERNAL TABLE `cloudtrail-table`(
`eventversion` string,
`useridentity` struct<type:string,principalid:string,arn:string,accountid:string,invokedby:string,accesskeyid:string,username:string,sessioncontext:struct<attributes:struct<mfaauthenticated:string,creationdate:string>,sessionissuer:struct<type:string,principalid:string,arn:string,accountid:string,username:string>>>,
`eventtime` string,
`eventsource` string,
`eventname` string,
`awsregion` string,
`sourceipaddress` string,
`useragent` string,
`errorcode` string,
`errormessage` string,
`requestparameters` string,
`responseelements` string,
`additionaleventdata` string,
`requestid` string,
`eventid` string,
`resources` array<struct<arn:string,accountid:string,type:string>>,
`eventtype` string,
`apiversion` string,
`readonly` string,
`recipientaccountid` string,
`serviceeventdetails` string,
`sharedeventid` string,
`vpcendpointid` string)
PARTITIONED BY (
`account` string,
`region` string,
`timestamp` string)
ROW FORMAT SERDE
'com.amazon.emr.hive.serde.CloudTrailSerde'
STORED AS INPUTFORMAT
'com.amazon.emr.cloudtrail.CloudTrailInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://cloudtrail-bucket/AWSLogs/o-rgid/'
TBLPROPERTIES (
'projection.enabled'='true',
'projection.account.type'='enum',
'projection.account.values'='account1,account2,account3',
'projection.region.type'='enum',
'projection.region.values'='ap-northeast-1,ap-northeast-2,ap-northeast-3,ap-south-1,ap-southeast-1,ap-southeast-2,ca-central-1,eu-central-1,eu-north-1,eu-west-1,eu-west-2,eu-west-3,me-south-1,sa-east-1,us-east-1,us-east-2,us-west-1,us-west-2',
'projection.timestamp.type'='date',
'projection.timestamp.interval.unit'='DAYS',
'projection.timestamp.interval'='1',
'projection.timestamp.format'='yyyy/MM/dd',
'projection.timestamp.range'='2020/01/01,NOW',
'storage.location.template'='s3://cloudtrail-bucket/AWSLogs/o-rgid/${account}/CloudTrail/${region}/${timestamp}')
Code language: JavaScript (javascript)자, 이렇게 완성된 DDL을 이용해서 Athena에 테이블을 만들면 지정된 계정과 리전 전체를 포함하는 단일 테이블을 생성할 수 있습니다. 그리고 데이터 파이셔닝이 되어있으므로 해당 컬럼을 지정하여 보다 적은 데이터를 스캔함으로써 비용 절감과 속도 향상을 체감하실 수 있을 겁니다.