
빅데이터 처리를 위해서 스파크(Spark)가 인기를 끈 이유는 대용량 데이터를 병렬로 처리할 수 있다는 것입니다. 그래서 스파크를 처음에 접했을 때는 모든 작업이 병렬로 처리된다는 생각을 하게 되고, 이 때문에 스파크는 항상 병렬 처리를 한다고 믿었습니다. 물론 이것은 사실입니다. 그런데, 아래와 같은 워크로드를 가지는 경우를 생각해 봅시다.


처음에는 하나의 노드에서만 처리하다가 중간에 복잡한 데이터 처리 로직이 있어서 6대의 노드에서 처리가 되고, 다시 하나의 노드에서 처리되는 작업을 생각해 봅시다. 이러한 작업을 5개 실행하면 스파크는 보통 아래처럼 작업을 실행합니다.


썩 마음에 들지 않습니다. 작업 내의 데이터 처리는 병렬로 동작하지만, 작업 자체가 직렬로 처리되는 구조라서 리소스와 비용이 낭비되고 시간도 오래 걸립니다. 저처럼 클라우드 환경에서 작업하는 상황이라면 최대한 모든 리소스를 사용해서 비용을 절감하고 싶을 겁니다.
대부분의 작업자가 궁극적으로 원하는 워크로드는 빈 공간에 다른 작업이 병렬로 동작하는 구조일 것입니다. 그리고 스파크는 실제로 이것을 가능하게 하는 기능이 존재합니다. 저는 이것을 테트리스라고 표현했는데, 리소스를 최대한 끼워넣어서 클러스터가 최대 성능을 계속 발휘하도록 하는 것을 의미하며 이에 대한 워크로드는 아래와 같습니다.


작업 각각의 병렬 처리는 약화됐지만, 작업들 전체가 병렬 처리 됨으로써 사용 가능한 모든 리소스를 쓰면서 시간을 줄일 수 있습니다. 앞서 길이 50의 작업이 아래에서는 14로 줄어들었습니다. 시간으로 따지면 70%가 감소한 것입니다. 게다가 노드의 크기(수직 방향)를 늘림으로써 개별 작업의 병렬 처리를 강화하여 시간을 추가로 단축하는 것도 가능합니다.
Spark 작업 스케줄러
작업 스케줄러를 모를 때에는 스칼라(Scala)에서 ForkJoinPool을 이용해서 직접 병렬 작업 처리를 구현했었습니다. 방법은 간단합니다. Pool을 생성하고 병렬화된 List에 대해서 foreach 작업을 걸어줍니다.
val infoList = getList(Parameter).par
val forkJoinPool = new ForkJoinPool(15)
infoList.tasksupport = new ForkJoinTaskSupport(forkJoinPool)
infoList foreach { item =>
// do something what you want
}Code language: Scala (scala)그러면 foreach 문이 List의 작업을 Pool 사이즈에 맞춰서 동시에 실행하게 됩니다. 그런데, 문제가 있습니다! 스파크에서는 이렇게 실행할 경우에 스파크의 세션이 공유되기 때문에 변수들이 Executor 메모리에서 모두 뒤엉켜 버립니다. 그래서 스파크 세션을 나눠줘야 합니다.
val sparkMaster = SparkSession.builder.appName("test").getOrCreate()
val infoList = getList(Parameter).par
val forkJoinPool = new ForkJoinPool(15)
infoList.tasksupport = new ForkJoinTaskSupport(forkJoinPool)
infoList foreach { item =>
val spark = sparkMaster.newSession
// do something what you want
}Code language: Scala (scala)이런 식으로 세션을 나눠주면 foreach의 작업들이 분리되어 정상적인 처리가 가능해집니다.
그런데, 이런식으로 Pool 사이즈를 지정하고 직접 병렬 작업을 수행하게 할 필요가 없었습니다. 스파크는 작업 스케줄러를 제공하고 있기 때문에, 병렬 작업 처리를 리소스에 맞춰서 알아서 조절해주는 기능을 제공합니다. 해당 옵션을 제공하는 방법은 여러 가지가 있지만, 제일 간편한 방법으로 스파크 jar 내에서 모두 해결하는 방법을 이용했습니다. 먼저, 스파크 프로젝트의 Resources 폴더에 fair.xml을 생성합니다.
<?xml version="1.0"?>
<allocations>
<pool name="fair_pool">
<schedulingMode>FAIR</schedulingMode>
<weight>10</weight>
<minShare>0</minShare>
</pool>
</allocations>Code language: HTML, XML (xml)그 후에 스파크 세션을 생성하면서 아래와 같이 설정을 제공하고 foreach 문을 이용해서 병렬 작업 처리가 가능합니다.
val sparkMaster = SparkSession.builder.appName("test").getOrCreate()
sparkMaster.sparkContext.setLocalProperty("spark.scheduler.mode", "FAIR")
sparkMaster.sparkContext.setLocalProperty("spark.scheduler.allocation.file", getClass.getResource("/fair.xml").getPath)
sparkMaster.sparkContext.setLocalProperty("spark.scheduler.pool", "fair_pool")
val infoList = getList(Parameter).par
infoList foreach { item =>
val spark = sparkMaster.newSession
// do something what you want
}Code language: Scala (scala)그 결과는 아래와 같습니다.

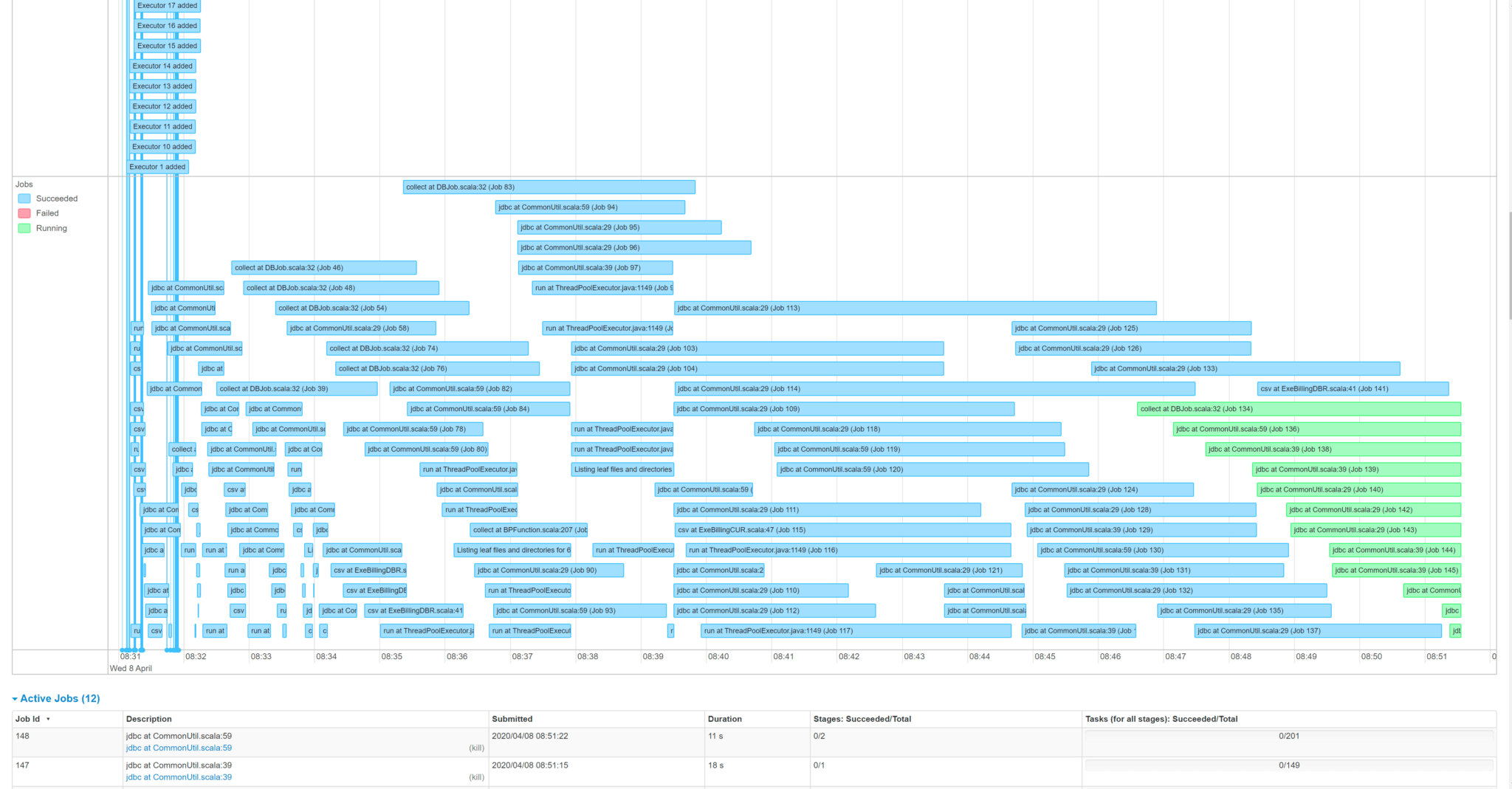
저는 이렇게 해서 8시간이 걸리던 배치 시간을 1시간까지 줄일 수 있었습니다. 병렬 작업 처리 + 노드 추가를 진행하였고, EMR의 스팟 인스턴스를 사용하니까 비용도 절감할 수 있었네요. 그에 따른 칭찬은 덤!
얼른 스파크 3.0이 나와서 더 훌륭한 기능들을 제공했으면 좋겠습니다. 스파크 만세!