
이전에 윈도우(Windows) 10 환경에서 스파크(Spark)를 설치하는 방법에 대한 글을 작성한 적이 있었는데, 한 번 셋팅해놓고 잘 쓰다가 컴퓨터를 포맷한다거나 하면서 환경 구성이 바뀌면 여간 골치아픈 것이 아닙니다. 그래서 도커(Docker) 이미지를 이용해서 손쉽게 서버를 올렸다 내렸다 하면서 사용할 수 있는 환경 구축에 대해서 알아보고자 합니다.
도커 설치
아래의 주소로 가셔서 도커 데스크탑을 설치합니다.
도커에서 Hyper-V를 이용하려면 윈도우 Pro 버전 이상이어야 하지만, 최신 도커버전은 윈도우의 WSL2를 지원하므로 Hyper-V를 쓸 수 없는 윈도우 Home 버전에서도 실행이 가능합니다. 약간의 기능 제약이 있지만, 계속 개선되고 있기 때문에 일반 사용자 입장에서는 크게 불편함을 느끼지 못하실 겁니다.
이를 위해서는 사전에 WSL2 환경이 구성되어 있어야 합니다. 아래 링크에서 어떻게 WSL2를 활성화 할 수 있는지 알 수 있습니다. 물론 WSL2 자체도 윈도우의 최신 버전에서만 돌아가므로 너무 옛날 버전을 사용하시면 곤란합니다.
WSL2 설정이 되어있는 상태에서 도커 데스크탑을 실행하면 WSL2를 이용해서 도커를 실행할 것인지 물어볼 겁니다. 혹은 설정에 가셔서 WSL2 옵션을 체크해주시면 됩니다.

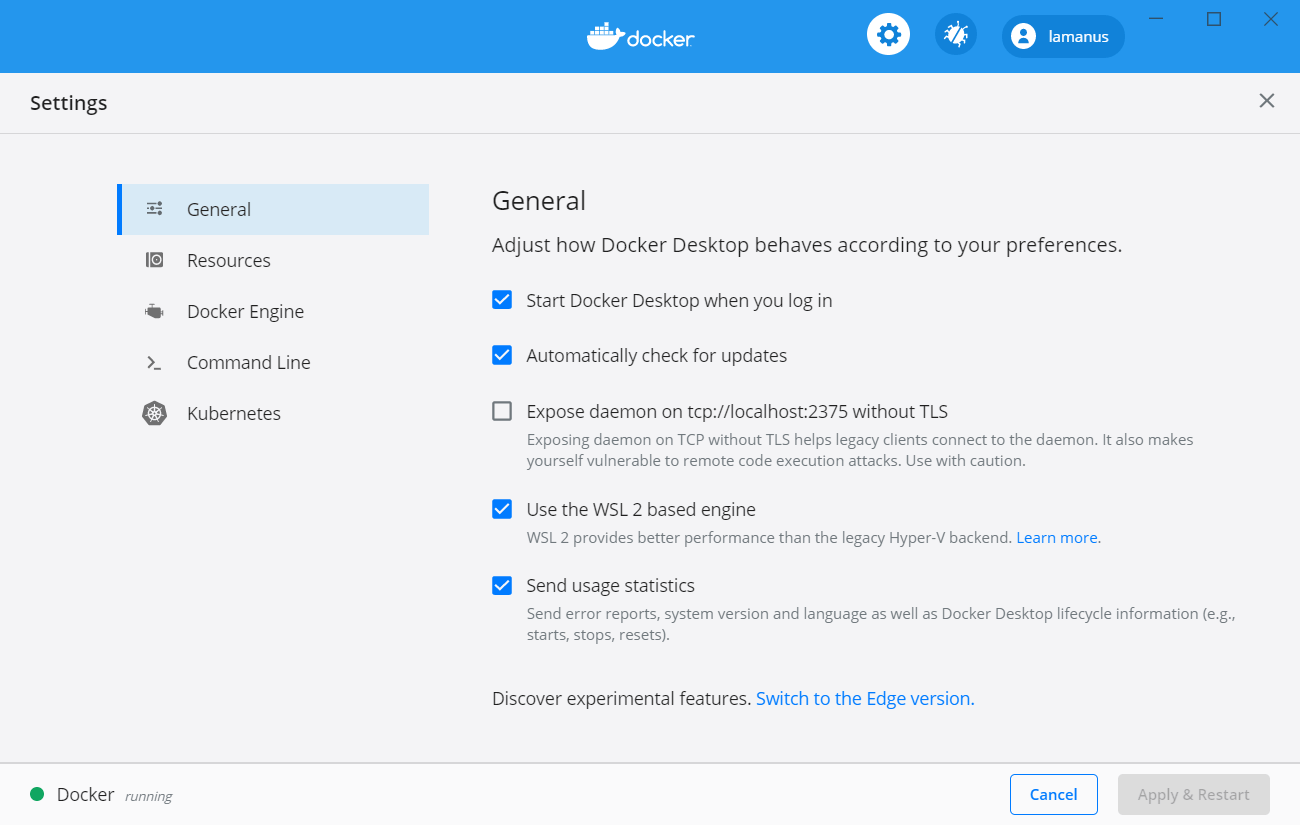
도커로 주피터 이미지 실행
도커가 정상적으로 설치되었으면 CMD나 git Bash의 쉘에서 docker 명령을 사용할 수 있습니다.
docker --version
Docker version 19.03.12, build 48a66213fe
Code language: CSS (css)그러면 이제 주피터(Jupyter) 이미지를 실행하기만 하면 됩니다. 주피터에서 공식적으로 제공하는 도커 이미지 라인업은 다음과 같습니다. [링크]
- jupyter/base-notebook
- jupyter/minimal-notebook
- jupyter/r-notebook
- jupyter/scipy-notebook
- jupyter/tensorflow-notebook
- jupyter/datascience-notebook
- jupyter/pyspark-notebook
- jupyter/all-spark-notebook
각각의 이미지에 어떤 라이브러리가 포함되는지는 링크로 직접 방문하셔서 확인하실 수 있습니다. 저는 딱 봐도 제일 강력하지만 당연히도 용량을 많이 차지할 것으로 보이는 마지막 이미지를 선택합니다.
도커 실행을 위해서 몇 가지 준비할 사항들이 있습니다.
- 주피터는 웹 서비스를 통해 연결되므로 포트를 연결해줘야 합니다.
- 저는 주피터 랩 (Juptyter Lab)을 이용할 것이므로 별도 옵션을 제공해야 합니다.
- 도커로 실행되는 주피터가 내 로컬 파일을 읽을 수 있도록 경로를 연결해줘야 합니다.
- 도커 이미지를 쉽게 구분하기 위해서 이름을 붙입니다.
- 도커가 실행되면 주피터도 항상 실행되어 있도록 옵션을 제공합니다.
이 모든 것을 요약한 한 줄의 코드는 다음과 같습니다.
docker run -p 8888:8888 -e JUPYTER_ENABLE_LAB=yes -v <local_path>:/home/jovyan --name jupyter --restart always jupyter/all-spark-notebook
Code language: HTML, XML (xml)명령 중간에 있는 <local_path>는 내가 주피터의 루트가 될 폴더를 컴퓨터에서 지정해주시면 됩니다. 제 컴퓨터를 예로 들자면, C:/Users/lamab/Documents/jupyter 라는 경로를 지정하여 해당 폴더에 파일을 넣으면 주피터에서도 파일이 추가되는 것을 확인할 수 있습니다.
명령을 실행하면 주피터 실행에 대한 로그가 올라오는데, 컨트롤 + C를 눌러 종료해도 됩니다. 종료하면서 로그에 적힌 토큰 값을 복사해둡니다. 그리고 아래 주소로 들어가서 비밀번호를 셋팅하고 토큰을 입력합니다.
http://localhost:8888/lab
암호는 사실 한 번만 입력해두면 되지만, 나중에 다시 나와도 쉽게 입력할 수 있도록 적당히 골라주세요.

주피터에서 스파크 사용
이제 주피터에서 스파크를 사용하는 방법을 알아보도록 하겠습니다. 스파크에서는 주피터에 대한 공식 커널 스펙을 따로 제공하지 않습니다. 대신에 사람들이 개발한 spylon-kernel 이라는 것을 이용해서 스파크를 이용할 수 있습니다. spylon-kernel은 scala 언어를 지원합니다.
커널이 시작되면서 이미 스파크 세션은 생성이 되어 있습니다.
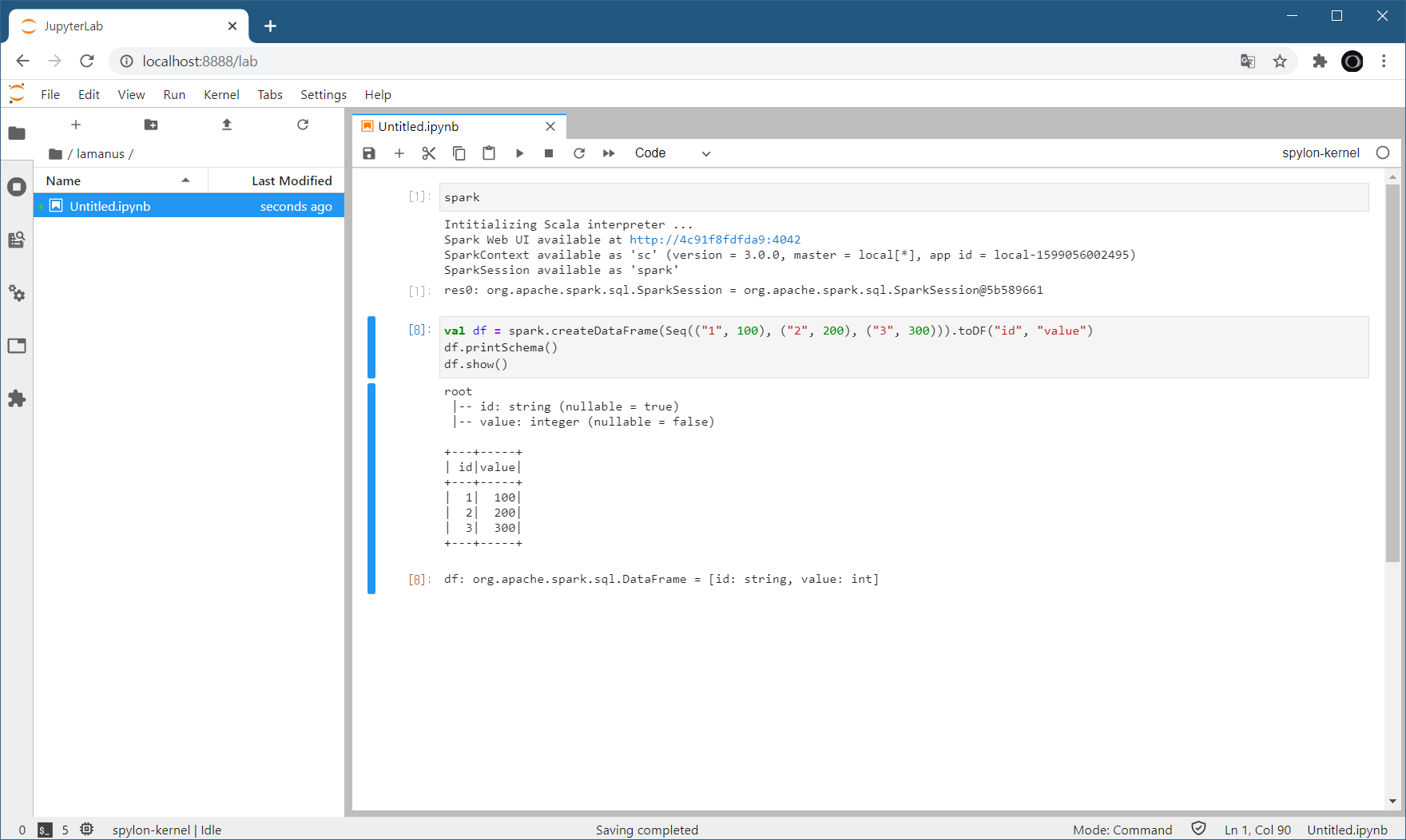
이처럼 스파크 데이터프레임을 생성하고 작업을 진행할 수 있습니다. 그리고, 파이썬 (Python)에서도 파이스파크 (PySpark)를 이용하여 스파크 사용이 가능합니다. 앞서 all-spark-notebook으로 선택했기 때문에 사전 준비는 모두 되어 있습니다.
import findspark
findspark.find()
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.master("local") \
.appName("Spark") \
.config("spark.sql.repl.eagerEval.enabled", True) \
.getOrCreate()
Code language: JavaScript (javascript)파이썬에서는 findspark 패키지를 이용해서 스파크 라이브러리를 찾은 다음에 파이스파크 패키지를 이용해서 스파크 세션을 생성할 수 있습니다. 중간에 옵션이 하나 들어갔는데, 이것은 파이썬 주피터에서 스파크 데이터프레임을 .show() 명령 없이도 이쁘게 보여주기 위함입니다.
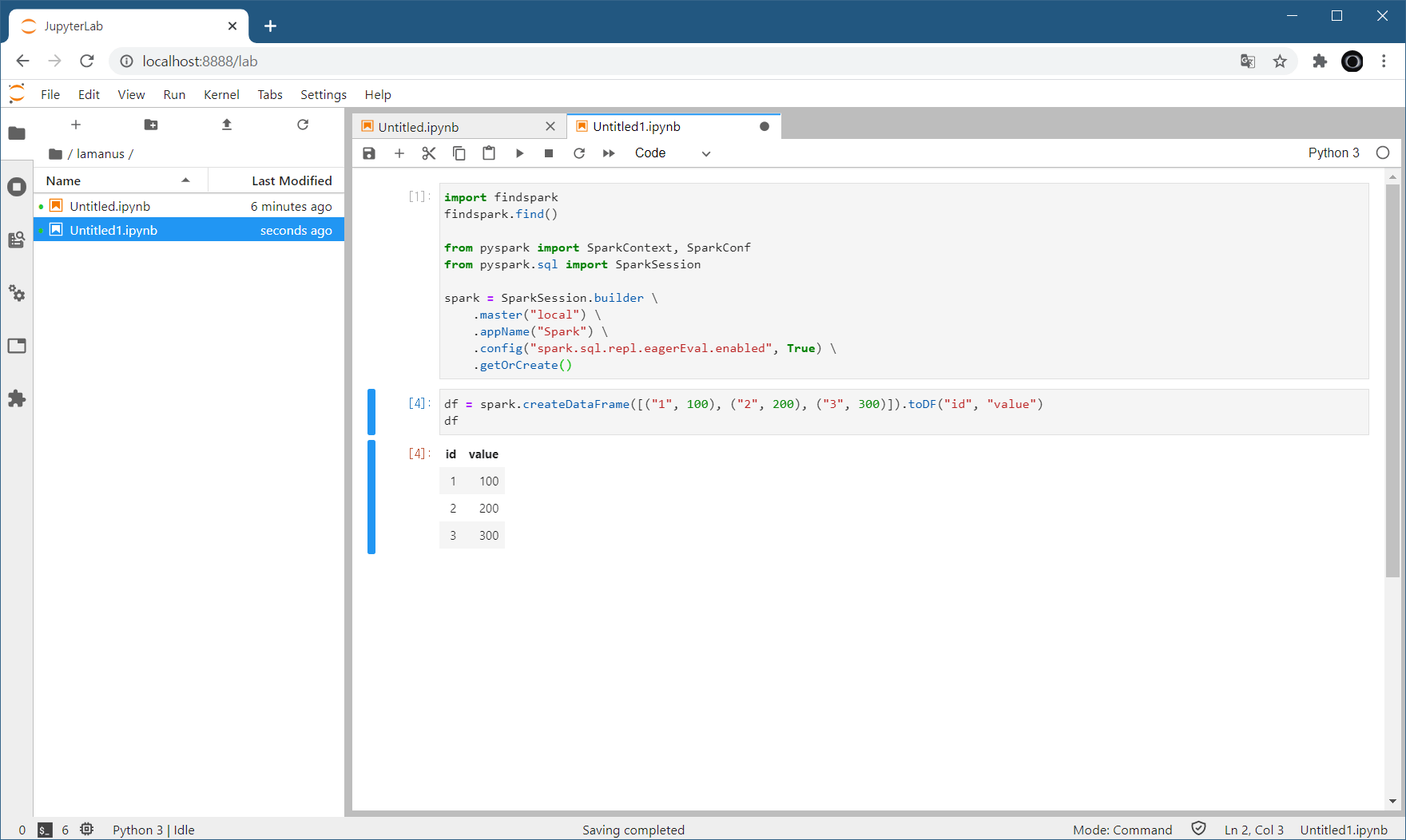
이처럼 파이썬을 이용하여 파이스파크를 사용하는 것도 매우 간단합니다. 사용해보시면 아시겠지만, 도커를 설치하고 WSL2 설정하는 것이, 이미지를 다운받아서 주피터를 실행하는 것보다 더 오래 걸릴 겁니다. 도커는 이미 강력하지만, 이제는 점점 더 많은 분야로 퍼져나가고 있어서 여러분도 도커를 이용하셔서 빠른 환경 구축에 도움이 되기를 바랍니다.