
Jupyter Lab에서 Spark 실행하기


스파크(Spark)로 개발을 하다보면 간단한 작업은 로컬에서 진행하고 싶은 경우가 있습니다. 겨우 이거 하나 하겠다고 스칼라(Scala)로 코드를 짜서 Jar를 만들고 스파크 클러스터에 작업을 제출하는 것은 너무나 불편하기만 합니다. 그래서 Jupyter Lab을 이용해서 간단한 스파크 코드를 작성하고 실행하는 과정을 소개하고자 합니다.
앞선 글에서 아나콘다를 이용해 Jupyter Lab은 설치를 했으므로 이 부분은 건너 뛰겠습니다. 스파크 실행을 위해서는 자바(Java) JDK와 스파크, 하둡 유틸 그리고 스파크 커널이 필요합니다.
자바 JDK 설치
제가 주로 사용하는 자바 버전은 1.8.0입니다. 여기서 세부 버전에 따라서 저작권 문제가 있는데요. 올해 4월에 라이센스 조항이 업데이트 되면서 상업적인 용도로 오라클 자바 를 이용하는 것은 좋은 선택이 아닙니다. 그래서 라이센스가 업데이트 되기 전인 202 버전을 설치해서 사용하기로 결정하였습니다. [링크] 매우매우 귀찮지만, 오라클에 로그인을 해야만 다운로드가 가능한 것 같습니다.
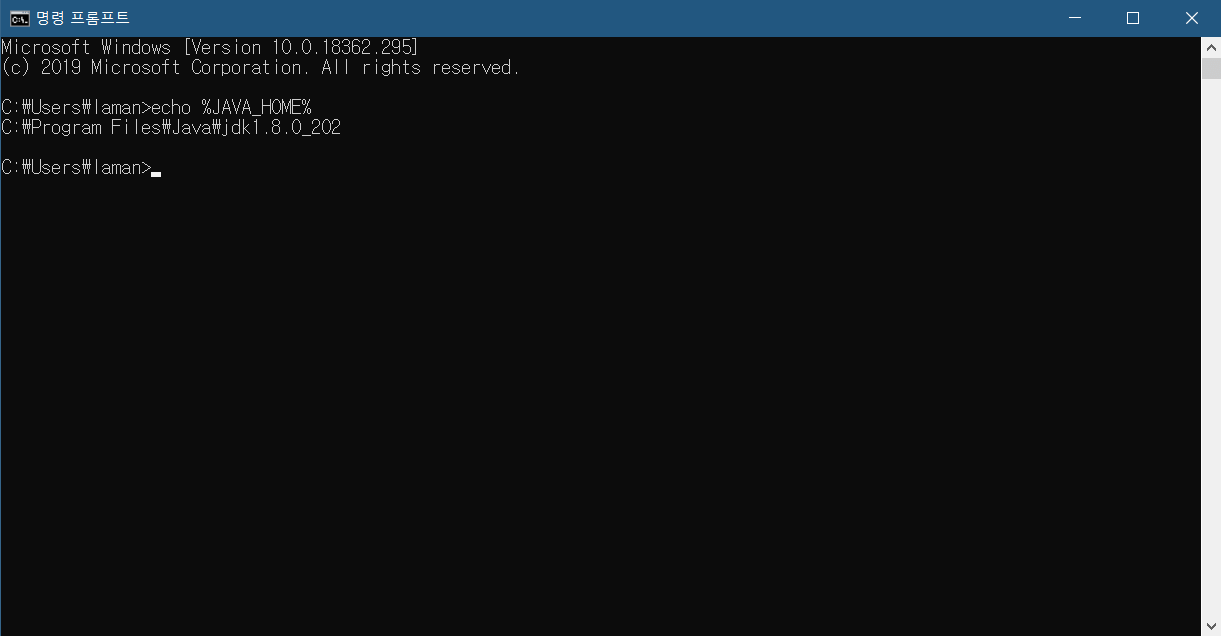
정상적으로 설치가 완료되었으면 위와 같이 자바 홈에 대한 환경 변수가 등록이 되어 있어야 합니다. 정상적으로 출력되지 않으면 아래에서 설명할 방법에 따라서 JAVA_HOME 환경 변수를 등록하시면 됩니다.
스파크 설치
이제 스파크를 설치해야 합니다. 스파크는 별도의 인스톨러가 없기 때문에, 그냥 바이너리 파일을 받아서 폴더에 넣고 환경 변수만 잡아주면 됩니다. 스파크는 하둡 2.7 이상의 버전에 대해서 사전에 빌드된 패키지를 이용하도록 하겠습니다. [링크]
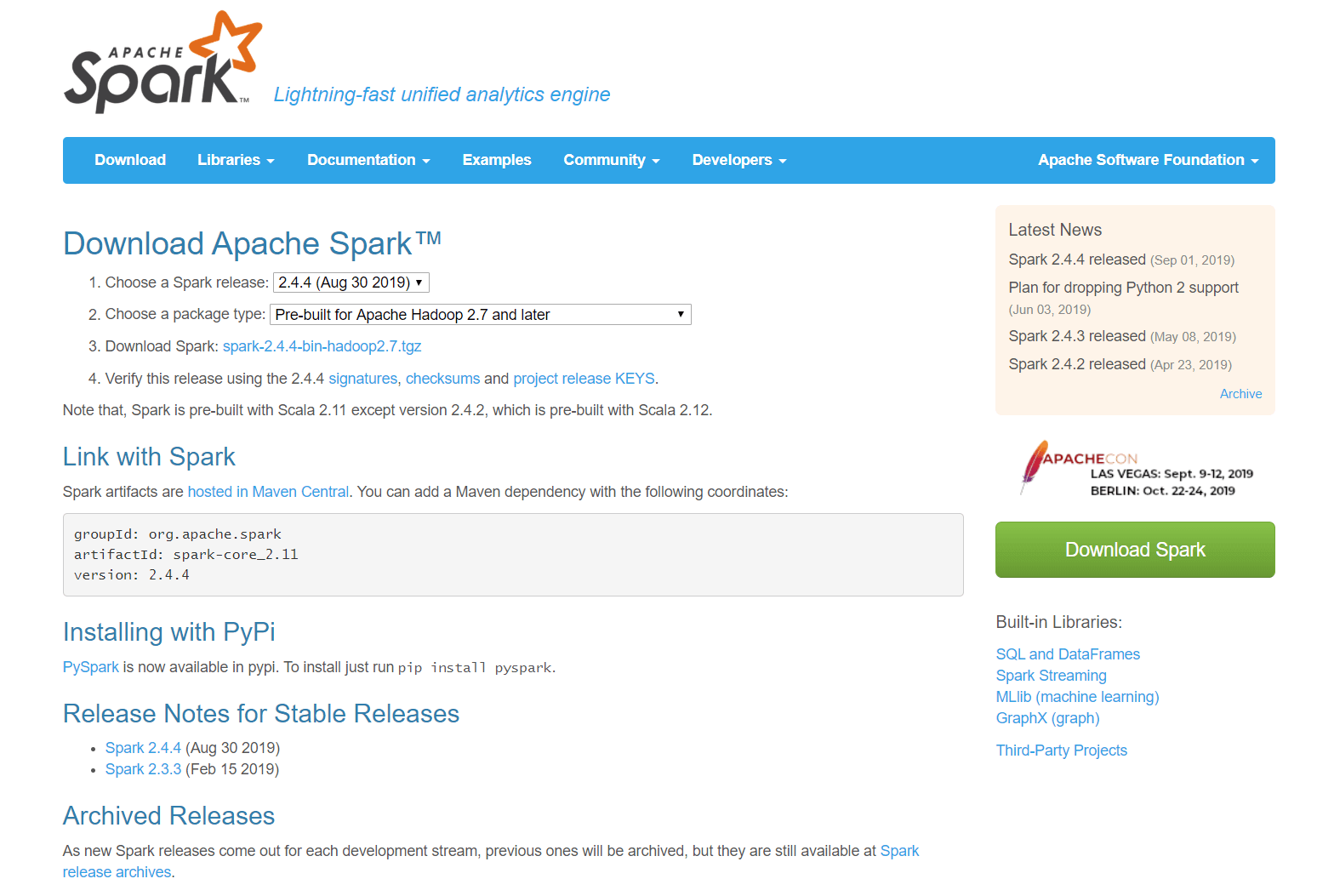
2.4.4 버전의 스파크에 대한 spark-2.4.4-bin-hadoop2.7.tgz를 다운받으면 됩니다. tgz 파일을 압축 해제하기 위해서는 별도의 압축 해제 프로그램이 필요할 수도 있습니다. 간단한 방법은 윈도우 10의 [제어판] > [프로그램 및 기능] > [Windows 기능 켜기/끄기] > [Linux용 Windows 하위 시스템]을 켜고 cmd에서 tar 명령을 이용하면 됩니다. 해당 설정을 셋팅하면 바로 재부팅이 필요합니다.
위 압축 파일을 다운받은 곳에 cmd를 열고, 아래 명령어를 통해서 압축 해제하면 됩니다.
tar -xzvf ./spark-2.4.4-bin-hadoop2.7.tgz그러면 압축 해제된 폴더가 생기는데, 이걸 고정적으로 이용하기 편하고 C:\Program Files 경로가 아닌 곳에 위치를 시킵니다. 관리자 권한으로 접근 가능한 경로는 매우 불편하기 때문에, 저는 C:\Users\%USERNAME%\Documents\spark 경로에 해당 폴더를 모두 옮겼습니다. 이렇게 폴더를 옮겼으면, [윈도우 키] + [Pause 키]를 눌러 [시스템] 화면으로 들어갑니다. 또는, 시작 버튼을 우클릭하여 [시스템]에 들어가고 거기에서 [시스템 정보]를 찾아 들어가면 됩니다. [시스템] 화면 좌측의 [고급 시스템 설정]에 들어가면 [환경 변수] 버튼을 볼 수 있습니다.
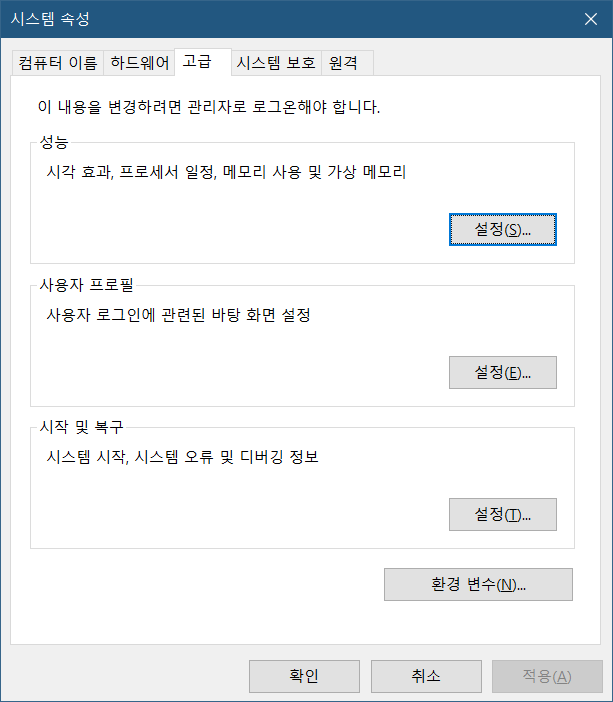
환경 변수에 들어가면 두 가지가 있습니다. 사용자 변수와 시스템 변수인데, 특별한 이유가 없으면 사용자 변수에 등록하면 됩니다. 다른 사용자도 사용하게 하고 싶으면 시스템 변수 등록을 하는 것이 맞지만, 그럴려면 관리자 권한 때문에 추후에 스파크 실행에 문제가 될 수 있습니다.
사용자 변수에 아래의 두 변수를 추가하고 Path에도 경로를 등록해야 합니다.
SPARK_HOME
C:\Users\\Documents\spark
HADOOP_HOME
C:\Users\\Documents\spark
Path
<기존 Path>;C:\Users\\Documents\spark\bin기존 Path가 여러 개라면 별도의 새로 만들기 버튼이 있으니 이걸로도 추가가 가능합니다. 부분은 컴퓨터에서 본인의 사용자 이름을 입력하시기 바랍니다.
여기서... 하둡(Hadoop)을 사용하지도 않는데, 왜 하둡 변수를 잡아주는지 의아할 수 있습니다. 그러나, 가만히 생각해보면 처음에 스파크를 다운로드할 때에 하둡에 대해서 사전 빌드된 패키지를 받은 것을 기억하실 겁니다. 그 의미는 하둡이 꼭 필요하다는 것입니다. 하지만 윈도우에서 하둡을 실제로 사용할 필요는 없습니다. WinUtils.exe 라는 실행파일 하나만 다운받아서 HADOOP_HOME 경로의 bin 폴더 안에 넣으면 됩니다. 별도의 하둡 폴더를 잡을 수도 있지만, 편의상 스파크 홈 폴더를 함께 이용하기로 하였습니다. [링크]
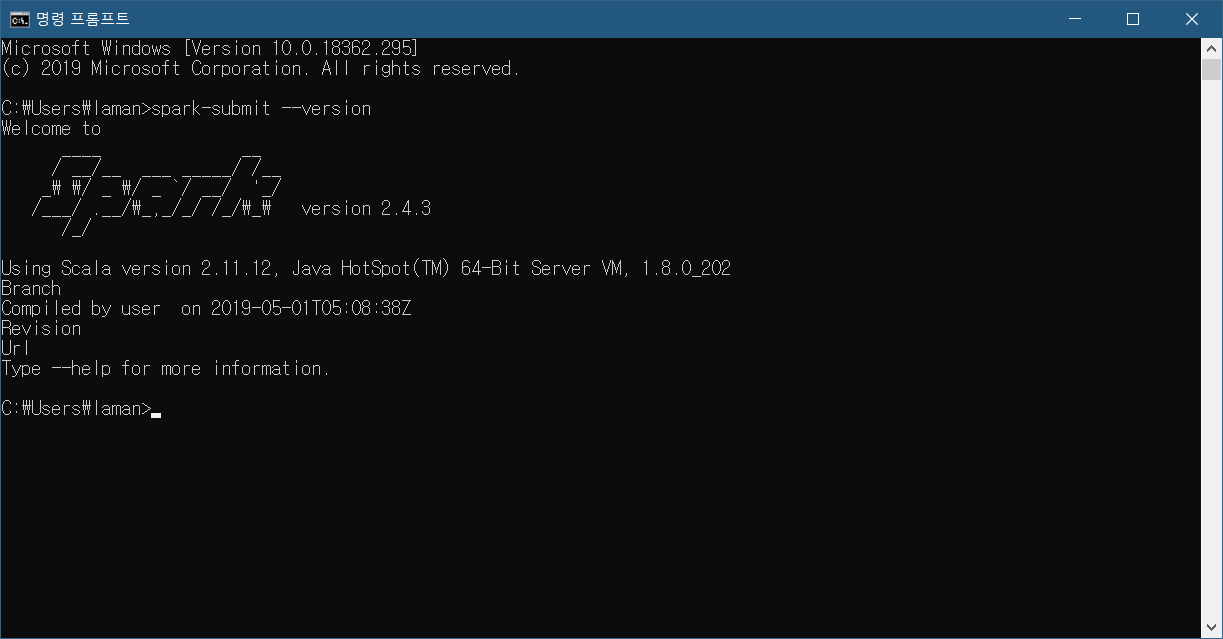
여기까지 잘 따라 오셨으면 cmd에서 스파크의 버전을 확인해볼 수 있습니다. 실행에 시간이 조금 걸릴 수도 있으니 참고하시기 바랍니다.
스파크 커널 설치하기
이제, 마지막 단계만 남았습니다. Jupyter Lab에 스파크 커널만 설치해서 연결하면 됩니다. 앞선 글과 같이 아나콘다를 이용해서 Python을 설치해놨으면 Jupyter Lab을 실행해서 터미널을 이용해 패키지 다운로드가 가능합니다. Jupyter Lab에서 터미널을 켜고 아래 명령어를 입력합니다.
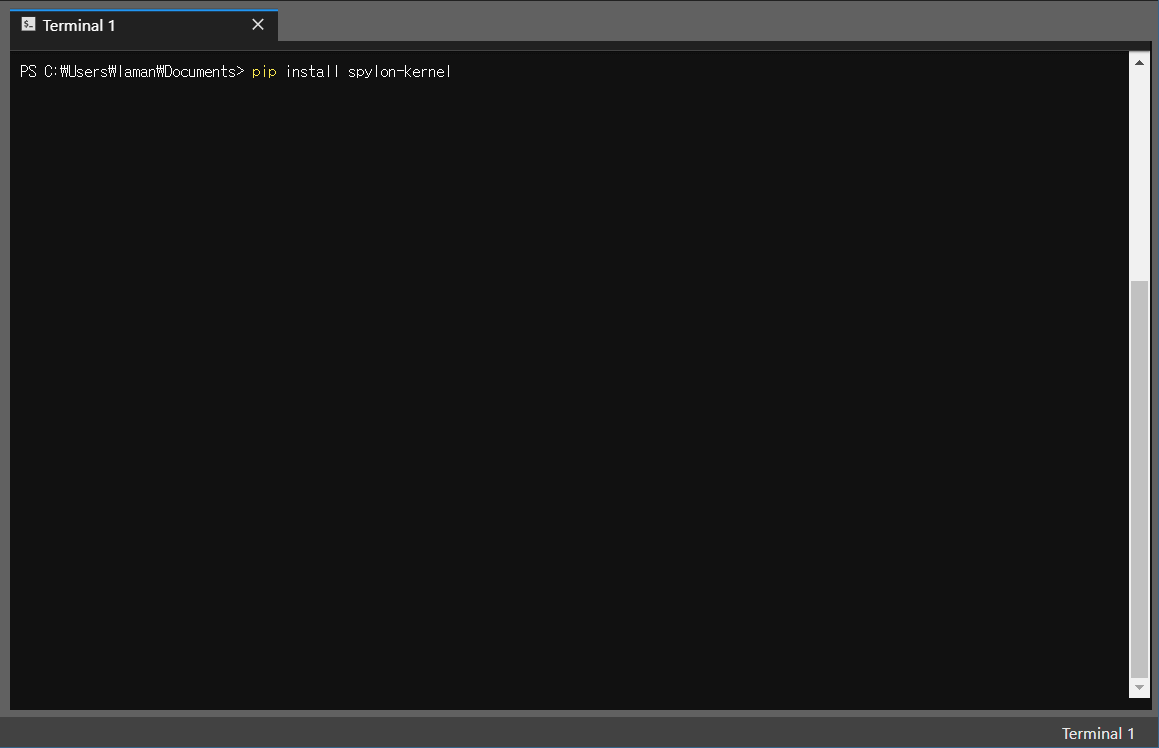
pip install spylon-kernel그 후에 아래 명령어를 통해서 kernel(커널) 설치가 가능합니다.
python -m spylon_kernel install설치가 완료된 다음에 Jupyter Lab을 새로고침하면 메인 화면에 스파크 커널이 추가된 것을 확인할 수 있습니다.
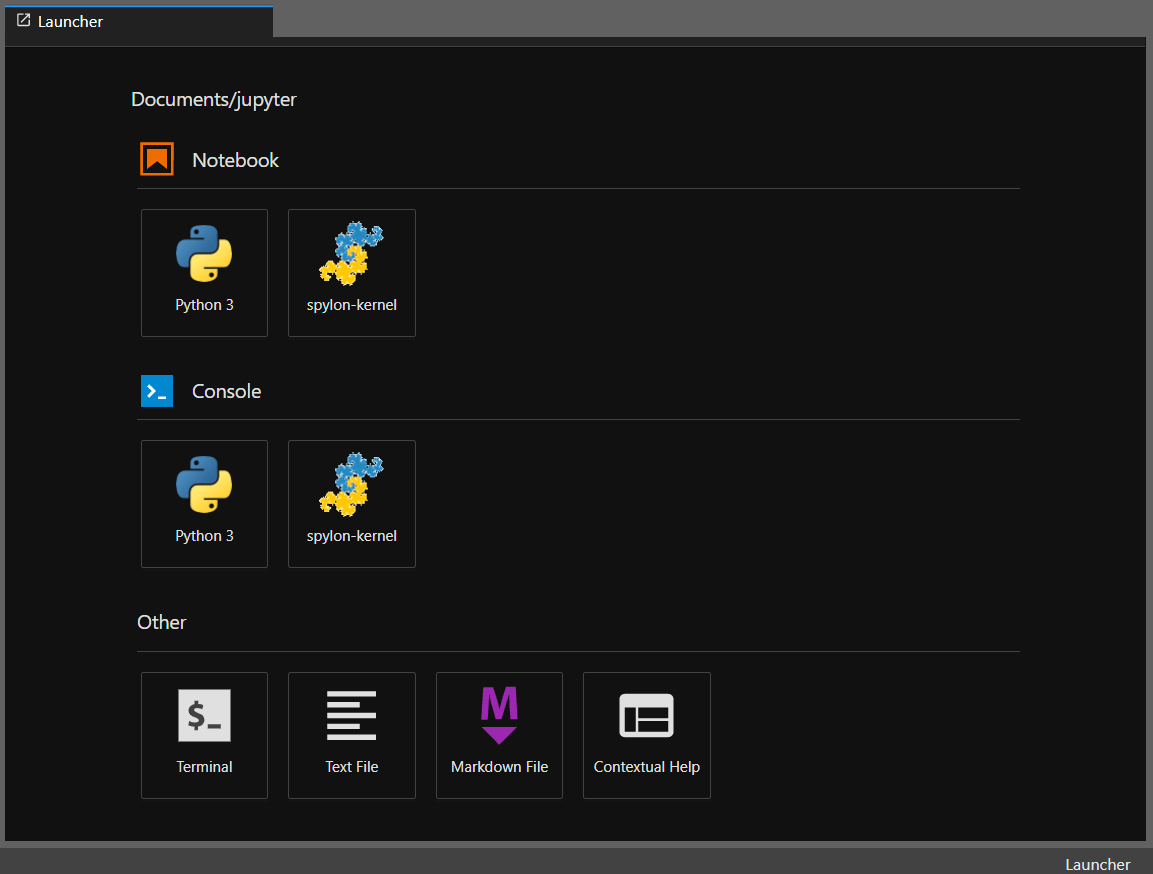
spylon-kernel을 눌러서 스파크가 정상 동작하는지 테스트를 합니다.
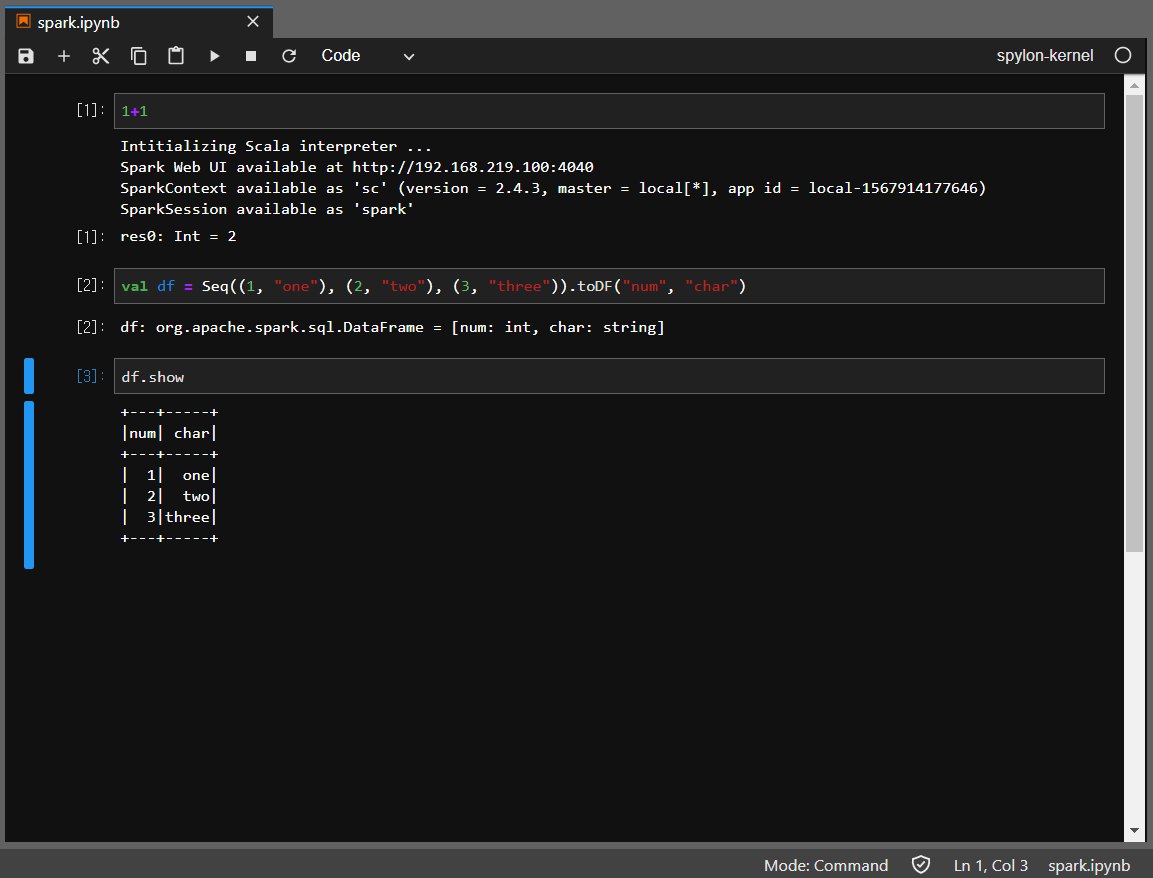
잘 돌아갑니다. 컬럼 명을 한글로 해봤더니 아무것도 출력이 되지 않는 버그가 있는 것 같습니다. CSV 등에서 가져올 때는 문제가 없었던 것 같은데... 이 부분만 유의하면 될 것 같습니다.
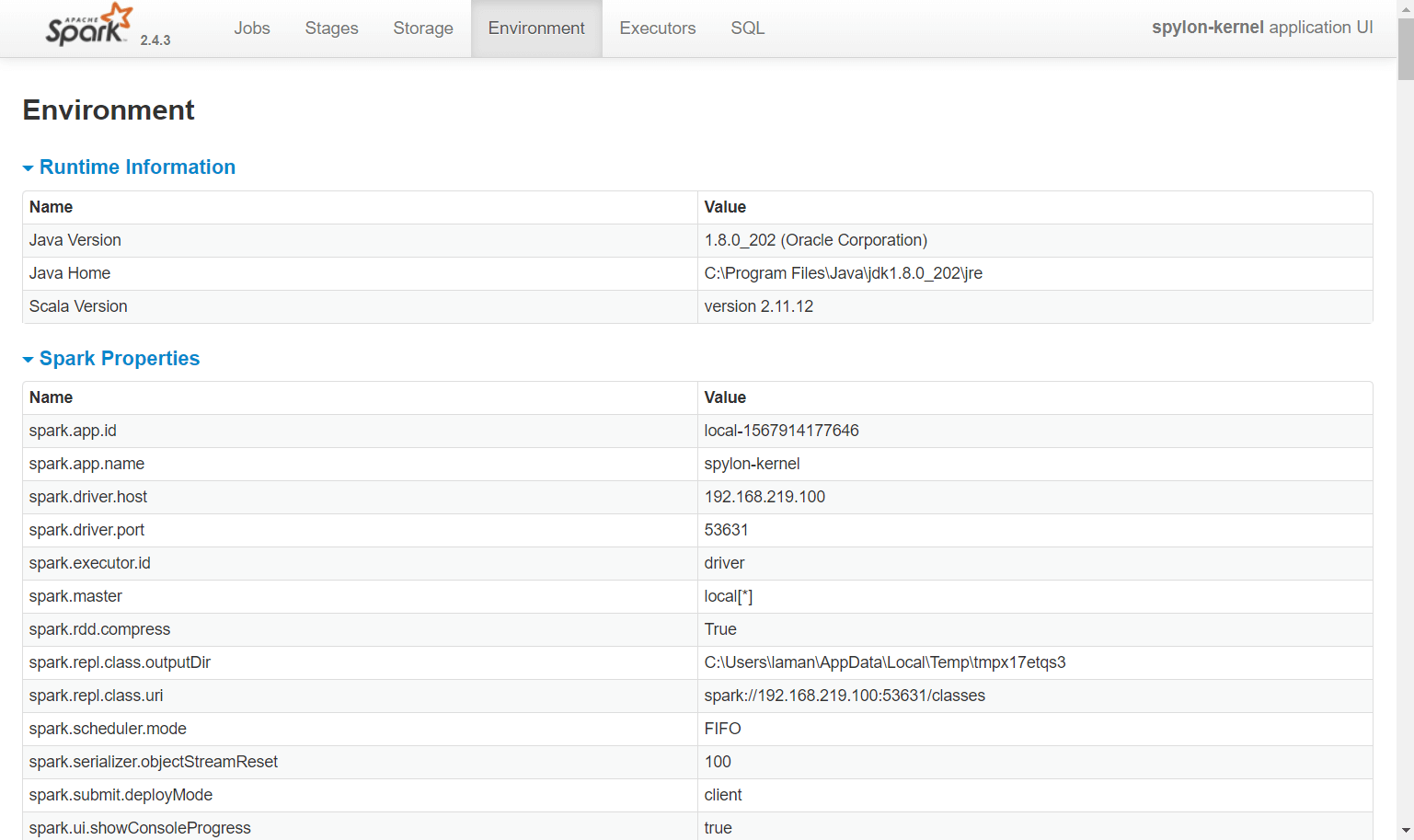
스파크 UI도 잘 나타납니다. 구축 완료!



